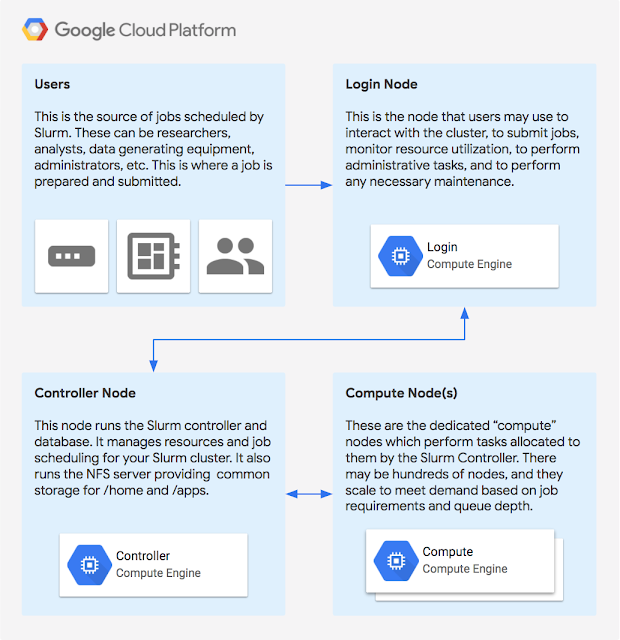
Hyperscale cloud platforms from the likes of Amazon, Microsoft and Google are great for running the kind of high-performance computing (HPC) projects that scientists in academia and the industry need for their simulations and analyses. Many of the workloads they run are, after all, easily parallelized across hundreds or thousands of machines. Often, though, the challenge is about how to create these clusters and how to then manage the workloads that run on them.
 To make this easier for the HPC community, Google today announced that it is bringing support for the open source Slurm HPC workload manager to its cloud platform (which is different from this Slurm). That’s the same piece of software that the many of the users in the TOP500 supercomputer list use, including the world’s biggest and fastest cluster to date, including the Sunway TaihuLight with its over 10 million computing cores.
To make this easier for the HPC community, Google today announced that it is bringing support for the open source Slurm HPC workload manager to its cloud platform (which is different from this Slurm). That’s the same piece of software that the many of the users in the TOP500 supercomputer list use, including the world’s biggest and fastest cluster to date, including the Sunway TaihuLight with its over 10 million computing cores.
For this project, Google teamed up with the experts at SchedMD, the company behind Slurm, to make it easier to run Slurm on Compute Engine. Using this integration, developers can easily launch an auto-scaling Slurm cluster on Compute Engine that runs based on the developers’ specifications. One interesting feature here is that users can also federate jobs from their on-premise cluster to the cloud when they need a bit of extra compute power.
Compute Engine currently offers machines with up to 96 cores and 624 GB of memory, so if you have the need (and money), building a massive compute cluster on GCP just got a little bit easier.
It’s worth noting that Microsoft, too, offers a template for deploying Slurm on Azure and that the tool has long supported AWS, too.